Känner du dig någonsin frustrerad på din dator?
Som systemadministratör har du säkert haft stunder där du bara vill slå näven i tangentbordet och skrika: "Vad är problemet?!". Men tänk om du faktiskt hade kunnat ställa just den frågan till Grafana – och fått ett användbart svar?
Hur blir detta möjligt?
Tänk dig att du ansluter ChatGPT till din monitoreringsmiljö och frågar vad som är på gång. Det är detta som är grundtanken - men istället för ChatGPT använder vi Ollama, en kraftfull Large Language Model (LLM) baserat på Metas LLaMA. Till skillnad från ChatGPT, körs Ollama lokalt och är helt gratis att installera.
Addera intelligens till din monitorering
En LLM kan på egen hand inte veta något om din IT-miljö. Det är här RAG (Retrieval-Augmented Generation) kommer in i bilden. Genom att kombinera en LLM med realtidsdata från Grafana (Grafana Mimir) eller Prometheus, kan vi överkomma klyftan mellan råa metrics och värdefulla insikter.
I denna blogg visar vi hur du kan integrera Ollama med RAG och Grafana Mimir för att förbättra din monitorering och få handlingsbara svar direkt från dina data.
Att notera är att den hårdvaruinställning som används i denna artikel får allt att fungera, men ger inte topprestanda. Den största flaskhalsen är att köra LLM:et på CPU:er istället för en GPU, vilket avsevärt saktar ner processen. Chansen att ha ett avancerat grafikkort liggandes oanvänt är ganska liten. Men med det sagt är det ändå användbart att få dessa insikter om din miljö - även om det kräver lite tålamod medan du väntar på svar.
Förutsättningar
I denna artikeln använder vi:
1 x Ubuntu 22.04 med 4GB RAM och 2 vCPUs (Server01)
1 x Ubuntu 22.04 med 16GB RAM och 4 (v)CPU Cores (Server02)
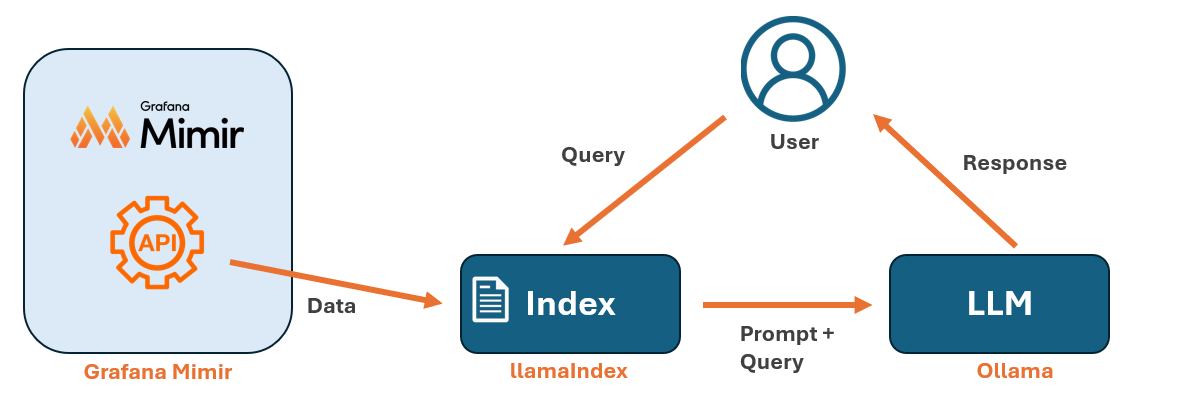
Översikt

Diagrammet ovan illustrerar hur komponenterna interagerar:
- Indexering av data: Först använder vi LlamaIndex för att bygga ett index från data som hämtas via Grafana Mimirs API. Du behöver återskapa indexet varje gång du vill lägga till ny data.
- Användarinteraktion: Användaren skickar en fråga (query) till LlamaIndex genom ett Python-skript.
- Hämtning och generering av svar: LlamaIndex hämtar relevant data från indexet och interagerar med Ollama, som bearbetar frågan och genererar ett svar.
Installera Grafana
Först sätter vi upp en Grafana LGTM Stack med testdata med hjälp av Docker Compose. Om du redan har en Grafana-miljö med Mimir installerad kan du använda den istället.
På Server01 öppnar du en terminal och installerar Docker Compose. Du kan hitta en installationsguide här.
När Docker Compose är installerat, klona då Intro till MLTP-arkivet till Server01 och navigera till arkivets mapp.
Slutligen kör du det nödvändiga Docker Compose-kommandot för att starta Grafana LGTM-stacken, som startar Grafana, Grafana Loki, Grafana Tempo och Grafana Mimir, och ger dig en komplett testmiljö.
git clone https://github.com/grafana/intro-to-mltp
cd intro-to-mltp
docker-compose up
Installera Ollama och LlamaIndex
Att installera Ollama är enkelt. På Server02 öppnar du en terminal och kör installationskommandot som visas på bilden nedan. Se till att du har nödvändiga behörigheter eller använd sudo om det krävs. För mer information kan du besöka den officiella Ollama hemsidan.
curl -fsSL https://ollama.com/install.sh | sh
Efter installationen av Ollama är nästa steg att ladda ner en lämplig modell för att bearbeta prompts. I den här artikeln använder vi Mistral-modellen, som vi importerar till Ollama med kommandot ollama pull.
Nästa steg är att konfigurera LlamaIndex. Till skillnad från traditionell programvara är LlamaIndex inte ett enda installerbart paket, utan en samling Python-bibliotek. Eftersom den har många beroenden rekommenderas det att först skapa en virtuell Python miljö (venv). Detta hjälper till att undvika konflikt mellan beroenden och sparar dig från frustrationen att felsöka kompatibilitetsproblem.
För att skapa en virtuell miljö kör du följande kommandon innan du installerar LlamaIndex. I exemplet nedan skapar vi en virtuell miljö som heter venv01, men du kan använda ett annat namn om du vill.
sudo apt-get install python3-pip
sudo pip3 install virtualenv
virtualenv venv01
source venv01/bin/activate
Efter att vi har aktiverat vår virtuella miljö kan vi installera LlamaIndex-paketen med pip.
pip install llama-index llama-index-llms-ollama llama-index-embeddings-huggingface sentence-transformerspip
Testa API:erna
Först kontrollerar vi om vi kan skicka kommandon till Ollama med Python biblioteken. Skapa en fil med namnet test_llama.py och lägg in koden nedan. Skriptet gör följande:
- Importerar de nödvändiga modulerna från llama_index för att arbeta med Ollama som en LLM.
- Initierar Ollama med mistral-modellen.
- Konfigurerar LlamaIndex för att använda Ollama-instansen globalt.
- Testar uppsättningen genom att skicka frågan "Vad är huvudstaden i Sverige?" till modellen och skriva ut svaret.
from llama_index.llms.ollama import Ollama
from llama_index.core import Settings
# Initialize Ollama as the LLM
llm = Ollama(model="mistral")
# Set up LlamaIndex to use Ollama globally
Settings.llm = llm
# Test Ollama completion
print(llm.complete("What is the capital of Sweden?"))
Utdata bör se ut ungefär så här:

Därefter kontrollerar vi om vi kan hämta data från Grafana Mimir. Skapa en fil med namnet test_mimir.py och lägg in Python-koden nedan. Ersätt server01 med rätt servernamn för din Mimir-endpoint. Skriptet gör följande:
Hämtar tillgängliga metric namn
- Skickar en begäran till Mimir API:et för att hämta en lista över alla tillgängliga metric namn.
- Om begäran lyckas skrivs det totala antalet metrics ut, samt ett urval av de första 10.
Hämtar tidsseriedata för varje metric
- Definierar ett tidsintervall (senaste timmen) med datapunkter varje minut.
- Loopar genom de första 50 metrics för att undvika att belasta systemet.
- Skickar API-förfrågningar för att hämta tidsseriedata för varje metric.
- Extraherar tidsstämplar, metric värden och tillhörande etiketter.
Lagra och bearbeta data
- Lagrar den insamlade datan i en Pandas DataFrame för vidare analys.
- Om datainsamlingen lyckas skrivs en förhandsvisning av de första 5 raderna ut.
import requests
import json
import time
import pandas as pd
# Mimir API Endpoints
MIMIR_LABELS_URL = "http://server01:9009/prometheus/api/v1/label/__name__/values"
MIMIR_QUERY_URL = "http://server01:9009/prometheus/api/v1/query_range"
### 1Fetch All Available Metric Names ###
response = requests.get(MIMIR_LABELS_URL)
# Check if request was successful
if response.status_code != 200:
print(f"Error fetching metrics: {response.status_code} - {response.text}")
exit(1)
data = response.json()
# Validate response structure
if "data" in data and isinstance(data["data"], list):
metric_names = data["data"]
print(f"Found {len(metric_names)} metrics.")
print("Sample metrics:", metric_names[:10]) # Show first 10 metrics
else:
print("No metrics found! Exiting.")
exit(1)
### Query Data for Each Metric ###
# Define the time range (last 1 hour)
end = int(time.time()) # Current timestamp
start = end - 3600 # 1 hour ago
step = "60s" # 1-minute interval
all_metric_data = []
# Loop through first 50 metrics to avoid overload
for metric in metric_names[:50]:
print(f"Fetching data for: {metric}")
params = {
"query": metric,
"start": start,
"end": end,
"step": step,
}
response = requests.get(MIMIR_QUERY_URL, params=params)
# Check if request was successful
if response.status_code != 200:
print(f"Error fetching {metric}: {response.status_code} - {response.text}")
continue # Skip this metric and move to the next one
metric_data = response.json()
# Check if data exists
if "data" in metric_data and "result" in metric_data["data"]:
for series in metric_data["data"]["result"]:
for value in series["values"]:
timestamp, metric_value = value
all_metric_data.append({
"timestamp": timestamp,
"metric_name": metric,
"value": float(metric_value),
"labels": json.dumps(series["metric"]),
})
### Convert Data to Pandas DataFrame ###
df = pd.DataFrame(all_metric_data)
if not df.empty:
print("Data successfully retrieved! Preview:")
print(df.head()) # Show first 5 rows
else:
print("No time-series data fetched from Mimir!")
Om allt fungerar som det ska bör du få utdata som liknar den nedan:
Om alla testskript fungerade som de ska, kan vi gå vidare och indexera data från Grafana Mimir.
Indexera Grafana Mimir data
Nu när vi har bekräftat att alla nödvändiga API:er fungerar som förväntat kan vi gå vidare och indexera data från Grafana Mimir.
Skapa en fil med namnet index_mimir.py och lägg in Python-koden nedan. Ersätt server01 med rätt servernamn för din Mimir-endpoint. Nedan följer en kortfattad förklaring av stegen i skriptet.
Konfigurera LlamaIndex med Ollama och HuggingFace Embeddings:
- Ställer in Ollama som språkmodell med mistral.
- Konfigurerar HuggingFace sentence-transformer-modell för att skapa textembedding.
Hämtar tillgängliga Prometheus metrics från Mimir:
- Skickar en HTTP GET-förfrågan till Mimirs API för att hämta alla tillgängliga metric namn.
- Om begäran lyckas extraheras och listas de första 10 metricsen.
- Om inga metrics hittas avslutas skriptet.
Hämtar tidsseriedata för metrics:
- Definierar ett tidsintervall på 1 timme med 1-minutssteg.
- Loopar igenom de första 50 metrics för att undvika att överbelasta systemet.
- Skickar förfrågningar till Mimirs API för att hämta tidsseriedata för varje metric.
- Extraherar tidsstämplar, metric namn, värden och etiketter, och lagrar dem i en lista.
Konverterar hämtad data till en Pandas DataFrame:
- Om ingen data är tillgänglig avslutas körningen.
- Annars skapas en Pandas DataFrame, och en förhandsvisning av de första raderna skrivs ut.
Förbereder data för LlamaIndex vektorsökning:
- Konverterar varje rad i DataFrame till ett LlamaIndex dokument.
- Varje dokument innehåller en textrepresentation av din metric data.
Indexerar data med LlamaIndex:
- Skapar en vektorbaserad indexering med den lokala embedding modellen.
- Sparar indexet på disk (./mimir_index) för att göra det beständigt och tillgängligt för senare användning.
Slutresultat:
- Bekräftar att Mimir-data har lyckats indexeras och är redo att användas med Ollama.
import requests
import json
import time
import pandas as pd
from llama_index.core import Document, VectorStoreIndex, Settings
from llama_index.llms.ollama import Ollama
# Try importing the HuggingFace embedding model
try:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding #LlamaIndex v0.9+
except ImportError:
from llama_index.embeddings import HuggingFaceEmbedding # LlamaIndex v1.0+
# Set LlamaIndex to use Ollama and a local embedding model
Settings.llm = Ollama(model="mistral") # Use Ollama for language processing
Settings.embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L6-v2") # Use local embeddings
# Mimir API Endpoints
MIMIR_LABELS_URL = "http://server01:9009/prometheus/api/v1/label/__name__/values"
MIMIR_QUERY_URL = "http://server01:9009/prometheus/api/v1/query_range"
### Fetch All Available Metric Names ###
response = requests.get(MIMIR_LABELS_URL)
# Check if request was successful
if response.status_code != 200:
print(f"Error fetching metrics: {response.status_code} - {response.text}")
exit(1)
data = response.json()
# Validate response structure
if "data" in data and isinstance(data["data"], list):
metric_names = data["data"]
print(f"Found {len(metric_names)} metrics.")
print("🔹 Sample metrics:", metric_names[:10]) # Show first 10 metrics
else:
print("No metrics found! Exiting.")
exit(1)
### Query Data for Each Metric ###
# Define the time range (last 1 hour)
end = int(time.time()) # Current timestamp
start = end - 3600 # 1 hour ago
step = "60s" # 1-minute interval
all_metric_data = []
# Loop through first 50 metrics to avoid overload
for metric in metric_names[:50]:
print(f" Fetching data for: {metric}")
params = {
"query": metric,
"start": start,
"end": end,
"step": step,
}
response = requests.get(MIMIR_QUERY_URL, params=params)
# Check if request was successful
if response.status_code != 200:
print(f"Error fetching {metric}: {response.status_code} - {response.text}")
continue # Skip this metric and move to the next one
metric_data = response.json()
# Check if data exists
if "data" in metric_data and "result" in metric_data["data"]:
for series in metric_data["data"]["result"]:
for value in series["values"]:
timestamp, metric_value = value
all_metric_data.append({
"timestamp": timestamp,
"metric_name": metric,
"value": float(metric_value),
"labels": json.dumps(series["metric"]),
})
### Convert Data to Pandas DataFrame ###
df = pd.DataFrame(all_metric_data)
if df.empty:
print("No time-series data fetched from Mimir! Exiting.")
exit(1) # Stop execution if no data is retrieved
print("Data successfully retrieved! Preview:")
print(df.head()) # Show first 5 rows
### Convert Data for LlamaIndex ###
documents = []
for _, row in df.iterrows():
doc_text = f"Timestamp: {row['timestamp']}, Metric: {row['metric_name']}, Value: {row['value']}, Labels: {row['labels']}"
documents.append(Document(text=doc_text))
# Create LlamaIndex Vector Store using local embeddings
index = VectorStoreIndex.from_documents(documents)
# Save Index
index.storage_context.persist(persist_dir="./mimir_index")
print("Mimir data successfully indexed for Ollama!")
Våra data prompts
Nu när vårt index är klart kan vi gå vidare till att ställa frågor till modellen. För att göra detta behöver vi använda ett Python-skript. Lägg in Python koden i en fil med namnet prompt_mimir.py.
import os
import argparse
from llama_index.core import load_index_from_storage, StorageContext, Settings
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# Force multi-threading
os.environ["OMP_NUM_THREADS"] = str(os.cpu_count())
os.environ["MKL_NUM_THREADS"] = str(os.cpu_count())
os.environ["OPENBLAS_NUM_THREADS"] = str(os.cpu_count())
os.environ["NUMEXPR_NUM_THREADS"] = str(os.cpu_count())
# Parse command-line arguments
parser = argparse.ArgumentParser(description="Query LlamaIndex using Ollama.")
parser.add_argument("query", type=str, help="The query to ask the index.")
args = parser.parse_args()
# Set LlamaIndex to use Ollama as LLM with higher timeout and max threads
Settings.llm = Ollama(model="mistral", request_timeout=120, num_threads=0) # Use all CPU cores
Settings.embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L6-v2")
# Load storage context before loading the index
storage_context = StorageContext.from_defaults(persist_dir="./mimir_index")
# Load existing index with storage context
index = load_index_from_storage(storage_context=storage_context)
# Create a retriever from the index
retriever = index.as_retriever()
# Create query engine using the retriever
query_engine = RetrieverQueryEngine(retriever=retriever)
# Use the query from the command-line argument
response = query_engine.query(args.query)
# Print the response
print("\n ^=^t^m Query:", args.query)
print(" ^=^r Response:", response)
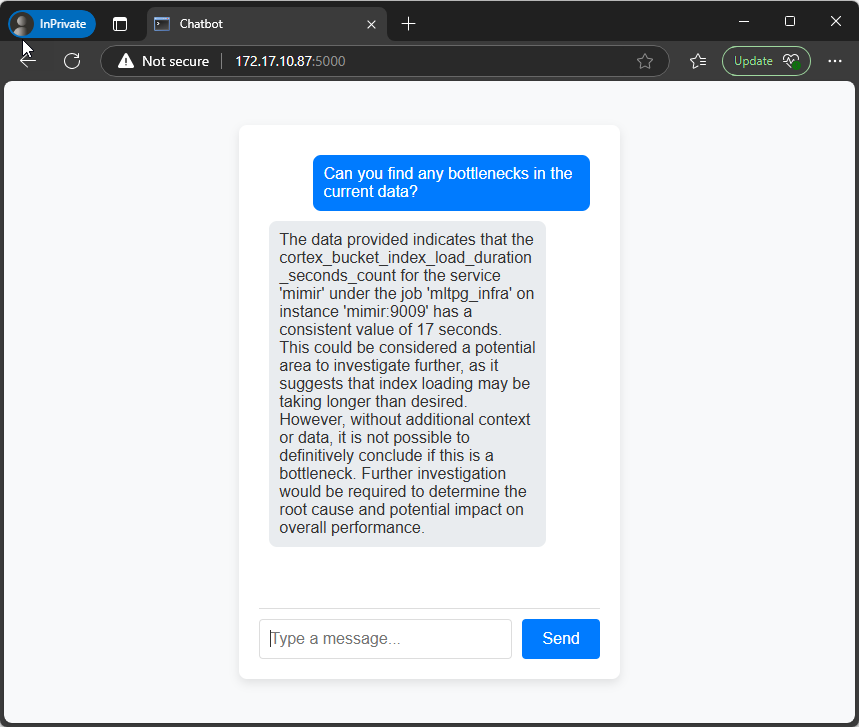
Nu kan du ställa frågor till modellen enligt exemplet nedan:
python3 prompt_mimir.py "What is taking most resources? Give the timestamps in human readable dates and give me the name of the metrics"
Om allt fungerade som det ska bör outputen se ut ungefär som i skärmdumpen nedan.

Sammanfattning
Genom att koppla ihop Ollama med RAG och Grafana Mimir har vi förvandlat råa metrics till något som du faktiskt kan kommunicera med. Att köra en LLM på enbart CPU går kanske inte supersnabbt, men trots viss fördröjning är det värdefullt att kunna få meningsfulla insikter bara genom att ställa en fråga till LLM:en.
Med lite optimering – som att lägga till en GPU – kan du göra uppsättningen betydligt snabbare.
Vill du prata Grafana med oss?

Inga kommentarer än
Berätta vad du tänker