
geschreven door Vincent de Vries op 11 maart 2025 14:47:19 CET
Ooit jezelf betrapt op schreeuwen tegen je monitor?
Als systeembeheerder heb je vast weleens gefrustreerd op je toetsenbord geslagen en gedacht: "Wat is jouw probleem?!" Maar wat als je die vraag rechtstreeks aan Grafana kon stellen—en ook nog eens nuttig antwoord kreeg?
Hoe kan je dit mogelijk maken?
Stel je voor dat je ChatGPT koppelt aan je monitoringomgeving en gewoon kunt vragen wat er aan de hand is. Dat is het idee—maar in plaats van ChatGPT gebruiken we Ollama, een krachtige Large Language Model (LLM) gebaseerd op Meta’s LLama. In tegenstelling tot ChatGPT draait Ollama lokaal en is volledig gratis te gebruiken.
Intelligentie toevoegen aan je monitoring
Een LLM weet natuurlijk niet uit zichzelf iets over jouw IT-omgeving. Daar komt RAG (Retrieval-Augmented Generation) om de hoek kijken. Door een LLM te combineren met realtime data uit Grafana (Grafana Mimir) of Prometheus, slaan we de brug tussen ruwe metrics en bruikbare inzichten.
In dit artikel laten we zien hoe je Ollama kunt integreren met RAG en Grafana Mimir om je monitoring naar een hoger niveau te tillen en direct bruikbare antwoorden over je data te krijgen.
Let op: De hardwareconfiguratie in dit artikel is voldoende om alles draaiende te krijgen, maar verwacht geen topprestaties. De grootste bottleneck is het draaien van de LLM op een CPU in plaats van een GPU, wat de verwerking aanzienlijk vertraagt. De kans dat je zomaar een high-end GPU hebt liggen is natuurlijk klein. Toch is het enorm bevredigend om waardevolle inzichten uit je omgeving te krijgen—zelfs als je even moet wachten op een antwoord.
Prerequisites
De volgende hardware wordt in dit artikel gebruikt:
1 x Ubuntu 22.04 met 4GB RAM en 2 vCPU's (Server01)
1 x Ubuntu 22.04 met 16GB RAM en 4 (v)CPU Cores (Server02)
Overview

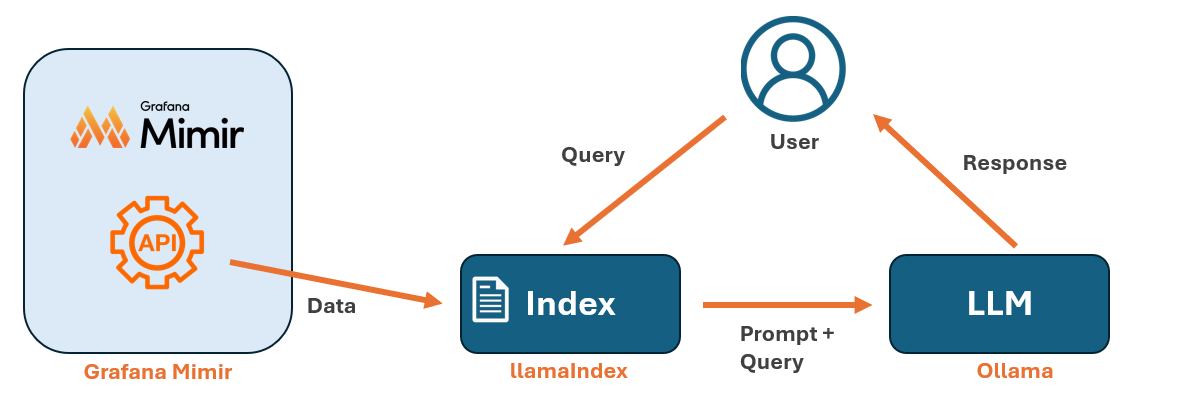
Het bovenstaande diagram illustreert hoe de componenten met elkaar samenwerken:
- Indexeren van gegevens: Eerst gebruiken we LlamaIndex om een index op te bouwen van de gegevens die worden opgehaald via de Grafana Mimir API. Je moet de index opnieuw opbouwen telkens wanneer je nieuwe gegevens wilt toevoegen.
- Gebruikersinteractie: De gebruiker draait een query in LlamaIndex via een Python script.
- Ophalen en genereren van een antwoord: LlamaIndex haalt relevante gegevens op uit de index en communiceert met Ollama, die de query verwerkt en een antwoord genereert.
Grafana installeren
Eerst installeren we een Grafana LGTM-stack met testgegevens via Docker Compose. Als je al een eigen Grafana omgeving hebt met daarin Mimir geïnstalleerd, kun je die in plaats van de LGTM-stack gebruiken.
Open een terminal op Server01 en installeer Docker Compose. Je kunt hiervoor een online handleiding volgen voor de installatie-instructies.
Zodra Docker Compose is geïnstalleerd, kloon je de Intro to MLTP-repository naar Server01 en navigeer je naar de map van de repository.
Voer ten slotte het benodigde Docker Compose commando uit om de Grafana LGTM-stack te starten. Dit zal Grafana, Grafana Loki, Grafana Tempo en Grafana Mimir opzetten, zodat je een complete testomgeving tot je beschikking krijgt.
Ollama en LlamaIndex installeren
Het installeren van Ollama is eenvoudig. Open op Server02 een terminal en voer het installatiecommando uit zoals in de onderstaande snippet. Zorg ervoor dat je over de juiste rechten beschikt of gebruik indien nodig sudo. Voor meer details kun je de officiële Ollama-pagina bezoeken.
Na de installatie van Ollama is de volgende stap het downloaden van een geschikt model voor het verwerken van prompts. In dit artikel gebruiken we het Mistral model, dat we in Ollama importeren met het commando ollama pull.
Vervolgens moeten we LlamaIndex instellen. In tegenstelling tot normale software is LlamaIndex een verzameling van Python libraries. Omdat LlamaIndex veel dependencies heeft, wordt sterk aanbevolen om eerst een Python virtual environment (venv) aan te maken. Dit helpt om dependency conflicten te voorkomen.
Om een virtual environment op te zetten, voer je de onderstaande commando’s uit voordat je LlamaIndex installeert. In het onderstaande voorbeeld maken we een virtual environment aan met de naam venv01, maar je kunt een andere naam gebruiken als je dat wilt.
Na het activeren van onze virtuele omgeving kunnen we de LlamaIndex packages installeren met pip.
Het testen van de API's
Laten we eerst controleren of we Ollama kunnen gebruiken met behulp van de Python libraries. Plaats de onderstaande Python code in een bestand genaamd test_llama.py. Dit script doet het volgende:
- Importeert de benodigde modules uit llama_index om met Ollama als LLM te werken.
- Initialiseert Ollama met het mistral model.
- Configureert LlamaIndex om de Ollama instantie globaal te gebruiken.
- Test de setup door het model de vraag te stellen: "What is the capital of Sweden? en de respons af te drukken.
NB: Je kan de prompts ook in Nederlands invoeren, maar je zal een ENgels antwoord krijgen.
De ouput van het antwoord zou er ongeveer zo uit moeten zien:

Vervolgens gaan we controleren of we gegevens kunnen ophalen uit Grafana Mimir. Plaats de onderstaande Python-code in een bestand genaamd test_mimir.py en vervang server01 door de juiste servernaam voor jouw Mimir-endpoint. Het script voert de volgende taken uit:
Ophalen van alle beschikbare metrics
- Stuurt een request naar de Mimir API om een lijst op te halen van alle beschikbare metrics.
- Indien succesvol, wordt het totale aantal beschikbare metrics op het scherm weergegeven en worden de eerste 10 als voorbeeld weergegeven.
Tijdreeksgegevens opvragen voor elke metriek
- Definieert een tijdsbereik (laatste 1 uur) met datapunten op intervallen van 1 minuut.
- Loopt door de eerste 50 metrics (om overbelasting van het systeem te voorkomen).
- Stuurt API request om tijdreeks data op te halen voor elke metric.
- Extract de timestamp, metric en bijbehorende labels.
Gegevens opslaan en verwerken
- Slaat de verzamelde gegevens op in een Pandas DataFrame voor verdere verwerking.
- Drukt een voorbeeld af van de eerste 5 rijen als het ophalen van data succesvol was.
Als alles goed is gegaan zou de je onderstaande output moeten krijgen:
Als we er zeker van zijn dat de test scripts geen fouten geven, kunnen we de volgende stap nemen en Grafana Mimir data gaan indexeren met LlamaIndex.
Indexeren van Grafana Mimir-data
Plaats de onderstaande Python code in een bestand genaamd index_mimir.py en vervang server01 door de juiste servernaam voor je Mimir endpoint. Hieronder wordt een beknopte uitleg gegeven van de stappen in het script.
Configureren van LlamaIndex met Ollama en HuggingFace Embeddings:
- Stel Ollama in als het taalmodel, waarbij mistral wordt gebruikt.
- Configureert HuggingFace's sentence-transformer model voor tekstembedding.
Ophalen van beschikbare Prometheus-metric namen uit Mimir:
- Verstuurd een HTTP GET request naar de Mimir API om alle beschikbare metric namen op te halen.
- Als de request succesvol is, worden de eerste 10 metric namen weergegeven.
- Als er geen metrics worden gevonden, stopt het script.
Ophalen van tijdreeksgegevens voor metrics:
- Definieert een tijdsbereik van 1 uur met een interval van 1 minuut.
- Itereert over de eerste 50 metrics om overbelasting van het systeem te voorkomen.
- Query de Mimir API voor tijdreeks data van elke metric.
- Extraheert de timestamp, metric, waarde en labels en slaat deze op in een lijst.
Omzetten van opgehaalde data naar een Pandas DataFrame:
- Als er geen data beschikbaar is, stopt de uitvoering.
- Anders wordt een voorbeeldweergave van de eerste paar rijen afgedrukt.
Voorbereiden van data voor LlamaIndex-vectorzoekopdrachten:
- Zet elke rij in het DataFrame om naar een LlamaIndex-document.
- Elk document bevat een tekstuele representatie van de metric gegevens.
Indexeren van de data met LlamaIndex:
- Creëert een vectorgebaseerde index met het lokale embedding-model.
- Slaat de index op schijf op (./mimir_index), zodat deze later opnieuw kan worden gebruikt.
Eindresultaat:
Bevestigt dat de Mimir-data succesvol is geïndexeerd en klaar is voor gebruik met Ollama.
Onze data prompten
Met onze index kunnen we nu verder gaan met het prompten van ons model. Dit moeten we echter wel met een Python script doen. Plaats de Python code in een bestand genaamd prompt_mimir.py.
Met het script kan je de Ollama via de index nu prompten als volgt:
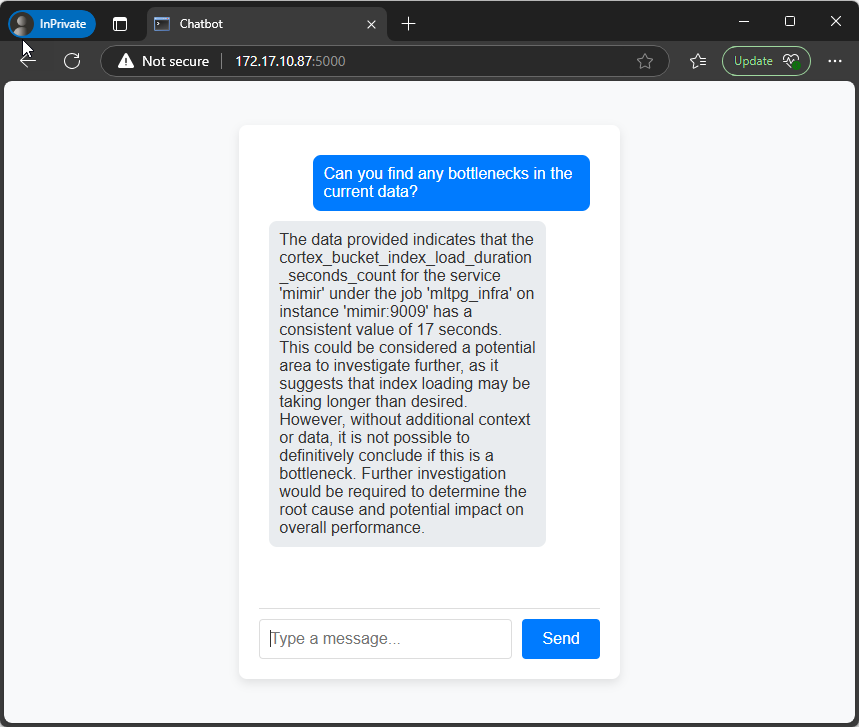
Als alles goed is gegaan, zou de uitvoer er ongeveer uit moeten zien als de onderstaande screenshot.

Conclusie
Door Ollama te koppelen aan Grafana Mimir door middel van een RAG model, hebben we ruwe metrics omgezet in iets dat je daadwerkelijk kunt bevragen met een LLM zoals Ollama. Natuurlijk draait een LLM niet snel op CPU’s, maar zelfs al is het langzaam, dan is het zeker leuk om te zien dat je waardevolle antwoorden kan krijgen door gewoon een vraag te stellen aan de LLM.
Met wat finetuning—zoals een GPU toevoegen—kun je deze setup een stuk sneller maken.
Wil je met ons over Grafana praten?
Dashboards met AI: Maak een eenvoudige prompt-UI voor LlamaIndex

Nog geen reacties
Vertel ons wat je denkt